UNIX distributions used to come with the system source code
in /usr/src. This is a concept which fascinates me: if you want
to change something in any part of your system, just make your change in the
corresponding directory, recomile, reinstall, and you can immediately see your
changes in action.
So, I decided I wanted to build a tool which can give you the impression of
that, without the downsides of additional disk space usage and slower update
times because of /usr/src maintenance.
The result of this effort is a tool called pk4 (mnemonic: get me
the package for ) which I just uploaded to Debian.
What distinguishes this tool from an apt source call is the
combination of a number of features:
pk4 defaults to the version of the package which is installed on your
system. This means when installing the resulting packages, you won t be
forced to upgrade your system in case you re not running the latest
available version.
In case the package is not installed on your system, the candidate
(see apt policy) will be used.
pk4 tries hard to resolve the provided argument(s): you can specify Debian
binary package names, Debian source package names, or file paths on your
system (in which case the owning package will be used).
pk4 comes with tab completion for bash and zsh.
pk4 caps the disk usage of the checked out packages by deleting the oldest ones
after crossing a limit (default: 2GiB).
pk4 allows users to enable supplied or shipped-with-pk4 hooks, e.g. git-init.
The git-init hook in particular results in an experience that reminds of
dgit,
and in fact it might be useful to combine the two tools in some way.
pk4 optimizes for low latency of each operation.
pk4 respects your APT configuration, i.e. should work in company intranets.
tries hard to download source packages, with fallback to snapshot.debian.org.
If you don t want to wait for the package to clear the NEW queue, you can get
it from here in the meantime:
You can find the sources and issue tracker
at https://github.com/Debian/pk4.
Here is a terminal screencast of the tool in action, availing the sources of
i3, applying a patch, rebuilding the package and replacing the installed
binary packages:
The image uses the linux-image-arm64 4.13.4-3 kernel, which provides HDMI output.
The image is now compressed using bzip2, reducing its size to 220M.
A couple of issues remain, notably the lack of WiFi and bluetooth support
(see wiki:RaspberryPi3 for details.
Any help with fixing these issues is very welcome!
As a preview version (i.e. unofficial, unsupported, etc.)
until all the necessary bits and pieces are in place to build images in a
proper place in Debian, I built and uploaded the resulting image. Find it at https://people.debian.org/~stapelberg/raspberrypi3/2017-10-08/.
To install the image, insert the SD card into your computer (I m assuming it s
available as /dev/sdb) and copy the image onto it:
Back in November, Michael Stapelberg blogged about running (pure) Debian on
the Raspberry Pi
3. This
is pretty exciting because Raspbian still provide 32 bit packages, so this
means you can run a true ARM64 OS on the Pi. Unfortunately, one of the major
missing pieces with Debian on the Pi3 at this time is broken video support.
A helpful person known as "SandPox" wrote to me in June to explain that they
had working video for a custom kernel build on top of pure Debian on the Pi,
and they achieved this simply by enabling CONFIG_FB_SIMPLE in the kernel
configuration. On request, this has since been enabled for official Debian
kernel builds.
Michael and I explored this and eventually figured out that this does work when
building the kernel using the upstream build instructions, but it doesn't
work when building using the Debian kernel package's build instructions.
I've since ran out of time to look at this more, so I wrote to request help
from the debian-kernel mailing
list, alas,
nobody has replied yet.
I've put up the dmesg.txt for a boot with the failing kernel, which might
offer some clues. Can anyone help figure out what's wrong?
Thanks to Michael for driving efforts for Debian on the Pi, and to SandPox for
getting in touch to make their first contribution to Debian. Thanks also to
Daniel Silverstone who loaned me an ARM64 VM
(from Scaleway) upon which I performed some of my
kernel builds.
Since debhelper/10.3, there has been a number of performance related changes. The vast majority primarily improves bulk performance or only have visible effects at larger input sizes.
Most visible cases are:
dh + dh_* now scales a lot better for large number of binary packages. Even more so with parallel builds.
Most dh_* tools are now a lot faster when creating many directories or installing files.
dh_prep and dh_clean now bulk removals.
dh_install can now bulk some installations. For a concrete corner-case, libssl-doc went from approximately 11 seconds to less than a second. This optimization is implicitly disabled with exclude (among other).
dh_installman now scales a lot better with many manpages. Even more so with parallel builds.
dh_installman has restored its performance under fakeroot (regression since 10.2.2)
For debhelper, this mostly involved:
avoiding fork+exec of commands for things doable natively in perl. Especially, when each fork+exec only process one file or dir.
bulking as many files/dirs into the call as possible, where fork+exec is still used.
caching / memorizing slow calls (e.g. in parts of pkgfile inside Dh_Lib)
adding an internal API for dh to do bulk check for pkgfiles. This is useful for dh when checking if it should optimize out a helper.
and, of course, doing things in parallel where trivially possible.
How to take advantage of these improvements in tools that use Dh_Lib:
If you use install_ file,prog,lib,dir , then it will come out of the box. These functions are available in Debian/stable. On a related note, if you use doit to call install (or mkdir ), then please consider migrating to these functions instead.
If you need to reset owner+mode (chown 0:0 FILE + chmod MODE FILE), consider using reset_perm_and_owner. This is also available in Debian/stable.
CAVEAT: It is not recursive and YMMV if you do not need the chown call (due to fakeroot).
If you need to remove files, consider using the new rm_files function. It removes files and silently ignores if a file does not exist. It is also available since 10.5.1.
If you need to create symlinks, please consider using make_symlink (available in Debian/stable) or make_symlink_raw_target (since 10.5.1). The former creates policy compliant symlinks (e.g. fixup absolute symlinks that should have been relative). The latter is closer to a ln -s call.
If you need to rename a file, please consider using rename_path (since 10.5). It behaves mostly like mv -f but requires dest to be a (non-existing) file.
Have a look at whether on_pkgs_in_parallel() / on_items_in_parallel() would be suitable for enabling parallelization in your tool.
The emphasis for these functions is on making parallelization easy to add with minimal code changes. It pre-distributes the items which can lead to unbalanced workloads, where some processes are idle while a few keeps working.
Credits:
I would like to thank the following for reporting performance issues, regressions or/and providing patches. The list is in no particular order:
Helmut Grohne
Kurt Roeckx
Gianfranco Costamagna
Iain Lane
Sven Joachim
Adrian Bunk
Michael Stapelberg
Should I have missed your contribution, please do not hesitate to let me know.
Filed under: Debhelper, Debian
Since debhelper/10.3, there has been a number of performance related changes. The vast majority primarily improves bulk performance or only have visible effects at larger input sizes.
Most visible cases are:
dh + dh_* now scales a lot better for large number of binary packages. Even more so with parallel builds.
Most dh_* tools are now a lot faster when creating many directories or installing files.
dh_prep and dh_clean now bulk removals.
dh_install can now bulk some installations. For a concrete corner-case, libssl-doc went from approximately 11 seconds to less than a second. This optimization is implicitly disabled with exclude (among other).
dh_installman now scales a lot better with many manpages. Even more so with parallel builds.
dh_installman has restored its performance under fakeroot (regression since 10.2.2)
For debhelper, this mostly involved:
avoiding fork+exec of commands for things doable natively in perl. Especially, when each fork+exec only process one file or dir.
bulking as many files/dirs into the call as possible, where fork+exec is still used.
caching / memorizing slow calls (e.g. in parts of pkgfile inside Dh_Lib)
adding an internal API for dh to do bulk check for pkgfiles. This is useful for dh when checking if it should optimize out a helper.
and, of course, doing things in parallel where trivially possible.
How to take advantage of these improvements in tools that use Dh_Lib:
If you use install_ file,prog,lib,dir , then it will come out of the box. These functions are available in Debian/stable. On a related note, if you use doit to call install (or mkdir ), then please consider migrating to these functions instead.
If you need to reset owner+mode (chown 0:0 FILE + chmod MODE FILE), consider using reset_perm_and_owner. This is also available in Debian/stable.
CAVEAT: It is not recursive and YMMV if you do not need the chown call (due to fakeroot).
If you need to remove files, consider using the new rm_files function. It removes files and silently ignores if a file does not exist. It is also available since 10.5.1.
If you need to create symlinks, please consider using make_symlink (available in Debian/stable) or make_symlink_raw_target (since 10.5.1). The former creates policy compliant symlinks (e.g. fixup absolute symlinks that should have been relative). The latter is closer to a ln -s call.
If you need to rename a file, please consider using rename_path (since 10.5). It behaves mostly like mv -f but requires dest to be a (non-existing) file.
Have a look at whether on_pkgs_in_parallel() / on_items_in_parallel() would be suitable for enabling parallelization in your tool.
The emphasis for these functions is on making parallelization easy to add with minimal code changes. It pre-distributes the items which can lead to unbalanced workloads, where some processes are idle while a few keeps working.
Credits:
I would like to thank the following for reporting performance issues, regressions or/and providing patches. The list is in no particular order:
Helmut Grohne
Kurt Roeckx
Gianfranco Costamagna
Iain Lane
Sven Joachim
Adrian Bunk
Michael Stapelberg
Should I have missed your contribution, please do not hesitate to let me know.
Filed under: Debhelper, Debian
Earlier today, I uploaded debhelper version 10.5.1 to unstable. The following are some highlights compared to version 10.2.5:
debhelper now supports the meson+ninja build system. Kudos to Michael Biebl.
Better cross building support in the makefile build system (PKG_CONFIG is set to the multi-arched version of pkg-config). Kudos to Helmut Grohne.
New dh_missing helper to take over dh_install list-missing/ fail-missing while being able to see files installed from other helpers. Kudos to Michael Stapelberg.
dh_installman now logs what files it has installed so the new dh_missing helper can see them as installed.
Improve documentation (e.g. compare and contrast the dh_link config file with ln(1) to assist people who are familiar with ln(1))
Avoid triggering a race-condition with libtool by ensuring that dh_auto_install run make with -j1 when libtool is detected (see Debian bug #861627)
Optimizations and parallel processing (more on this later)
There are also some changes to the upcoming compat 11
Use /run as run state dir for autoconf
dh_installman will now guess the language of a manpage from the path name before using the extension.
manpages now specify
their language in the HTML tag so that search engines can offer users the
most appropriate version of the manpage.
I contributed mandocd(8) to the mandoc project, which debiman
now uses for significantly faster manpage conversion (useful for disaster
recovery/development). An entire run previously took 2 hours on my workstation.
With this change, it takes merely 22 minutes. The effects are even more
pronounced on manziarly, the VM behind manpages.debian.org.
Thanks to Peter Palfrader (weasel) from the Debian System Administrators (DSA)
team, manpages.debian.org is now serving its manpages (and most of its
redirects) from Debian s static mirroring infrastructure. That way, planned
maintenance won t result in service downtime. I contributed README.static-mirroring.txt,
which describes the infrastructure in more detail.
The list above is not complete, but rather a selection of things I found worth
pointing out to the larger public.
There are still a few things I plan to work on soon, so stay tuned :).
A new version of the upstream firmware makes the Ethernet MAC address persist
across reboots.
Updated initramfs files (without updating the kernel) are now correctly copied
to the VFAT boot partition.
The initramfs s file system check now works as the required fsck binaries are
now available.
The root file system is now resized to fill the available space of the SD card
on first boot.
SSH access is now enabled, restricted via iptables to local network source
addresses only.
The image uses the linux-image-4.9.0-2-arm64 4.9.13-1 kernel.
A couple of issues remain, notably the lack of HDMI, WiFi and bluetooth support
(see wiki:RaspberryPi3 for details.
Any help with fixing these issues is very welcome!
As a preview version (i.e. unofficial, unsupported, etc.)
until all the necessary bits and pieces are in place to build images in a
proper place in Debian, I built and uploaded the resulting image. Find it at https://people.debian.org/~stapelberg/raspberrypi3/2017-03-22/.
To install the image, insert the SD card into your computer (I m assuming it s
available as /dev/sdb) and copy the image onto it:
manpages.debian.org launched
The debmans package I had so lovingly worked on
last month
is now officially abandoned. It turns out that another developer,
Michael Stapelberg wrote his own implementation from scratch,
called debiman.
Both software share a similar design: they are both static site
generators that parse an existing archive and call another tool to
convert manpages into HTML. We even both settled on the same converter
(mdoc). But while I wrote debmans in Python, debiman is written
in Go. debiman also seems much faster, being
written with concurrency in mind from the start. Finally, debiman is
more feature complete: it properly deals with conflicting packages,
localization and all sorts redirections. Heck, it even has a pretty
logo, how can I compete?
While debmans was written first and was in the process of being
deployed, I had to give it up. It was a frustrating experience because
I felt I wasted a lot of time working on software that ended up being
discarded, especially because I put so much work on it, creating
extensive documentation, an almost complete test suite and even
filing a detailed core infrastructure best practices report In the
end, I think that was the right choice: debiman seemed clearly
superior and the best tool should win. Plus, it meant less work for
me: Michael and Javier (the previous manpages.debian.org maintainer)
did all the work of putting the site online. I also learned a lot
about the CII best practices program,
flask, click
and, ultimately, the Go programming language itself, which I'll refer
to as Golang for brievity. debiman definitely brought Golang
into the spotlight for me. I had looked at Go before, but it seemed to
be yet another language. But seeing Michael beat me to rebuilding the
service really made me look at it again more seriously. While I really
appreciate Python and I will probably still use it as my language
of choice for GUI work and smaller scripts, but for daemons, network
programs and servers, I will seriously consider Golang in the future.
The site is now online at
https://manpages.debian.org/. I even got credited in the
about page which makes up
for the disappointment.
Wallabako downloads Wallabag articles on my Kobo e-reader
This obviously brings me to the latest project I worked on,
Wallabako, my first Golang program ever. Wallabako is basically a
client for the Wallabag application, which is
a free software "read it later" service, an alternative to the likes
of Pocket, Pinboard or
Evernote. Back in April,
I had looked downloading my "unread articles" into my new ebook
reader, going through convoluted ways like implementing
OPDS support into Wallabag, which turned out to be too difficult.
Instead, I used this as an opportunity to learn Golang. After reading
the quite readable golang specification over the weekend, I found
the language to be quite elegant and simple, yet very powerful. Golang
feels like C, but built with concurrency and memory (and to a certain
extent, type) safety in mind, along with a novel approach to OO
programming.
The fact that everything can be compiled in one neat little static
binary was also a key feature in selecting golang for this project, as
I do not have much control over the platform my E-Reader is running:
it is a Linux machine running under the ARM architecture, but beyond
that, there isn't much available. I couldn't afford to ship a Python
interpreter in there and while there are solutions there like
pyinstaller, I felt that it may be so easy to deploy on ARM. The
borg team had trouble building a ARM binary, restoring to tricks
like building on a Raspberry PI or inside an emulator. In comparison,
the native go compiler supports cross-compilation out of the box
through a simple environment variable.
So far Wallabako works amazingly well: when I "bag" a new article in
Wallabag, either from my phone or my web browser, it will show up on
my ebook reader then next time I open the wifi. I still need to "tap"
the screen to fake the insertion of the USB cable, but we're
working on automating that. I also need to make the installation
of the software much easier and improve the documentation, because so
far it's unlikely that someone unfamiliar with Kobo hardware hacking
will be able to install it.
Other work
According to Github, I filed a bunch of bugs all over the place (25
issues in 16 repositories), sent patches everywhere (13 pull requests
in 6 repositories), and tried to fix everythin (created 38 commits in
7 repositories). Note that excludes most of my work, which happens on
Gitlab. January was still a very busy month, especially considering I
had an accident which kept me mostly offline for about a week.
Here are some details on specific projects.
Stressant and a new computer
I revived the stressant
project and got a new computer. This is be covered in a
separate article.
Linkchecker forked
After much discussions, it was decided to fork the linkchecker
project, which now lives in its own organization. I still have to
write community guidelines and figure out the best way to maintain a
stable branch, but I am hopeful that the community will pick up the
project as multiple people volunteer to co-maintain the project. There
has already been pull requests and issues reported, so that's a good
sign.
Feed2tweet refresh
I re-rolled my pull requests to the feed2tweet project: last time
they were closed before I had time to rebase them. The author was okay
with me re-submitting them, but he hasn't commented, reviewed or
merged the patches yet so I am worried they will be dropped again.
At that point, I would more likely rewrite this from scratch than try
to collaborate with someone that is clearly not interested in doing
so...
Debian Long Term Support (LTS)
This is my 10th month working on Debian LTS, started by
Raphael Hertzog at Freexian. I took two months off last summer,
which means it's actually been a year of work on the LTS project.
This month I worked on a few issues, but they were big issues, so they
took a lot of time.
I have done a lot of work trying to backport the heading sanitization
patches for CVE-2016-8743. The
full report
explain all the gritty details, but I ran out of time and couldn't
upload the final version either. The issue mostly affects Apache
servers in proxy configurations so it's not so severe as to warrant an
immediate upload anyways.
A lot of my time was spent battling the tiff package. The
report
mentions fixes for 15 CVEs and I uploaded the result in the
DLA-795-1
advisory.
I also worked on a small update to graphics magic for
CVE-2016-9830 that is still pending because the issue is
minor and we're waiting for more to pile up. See the
full report
for details.
Finally, there was a small discussion surrounding tools to use
when building and testing update to LTS packages. The resulting
conversation was interesting, but it showed that we have a big
documentation problem in the Debian project. There are a lot of tools,
and the documentation is old and distributed everywhere. Every time I
want to contribute something to the documentation, I never know where
to start or go. This is why I wrote a separate
debian development guide instead of
contributing to existing documentation...
https://manpages.debian.org has been
modernized! We have just launched a major update to our manpage repository.
What used to be served via a CGI script is now a statically generated website,
and therefore blazingly fast.
While we were at it, we have restructured the paths so that we can serve all
manpages, even those whose name conflicts with other binary packages (e.g.
crontab(5) from cron, bcron or systemd-cron). Don t worry: the old URLs are
redirected correctly.
Furthermore, the design of the site has been updated and now includes
navigation panels that allow quick access to the manpage in other Debian
versions, other binary packages, other sections and other languages. Speaking
of languages, the site serves manpages in all their available languages and
respects your browser s language when redirecting or following a
cross-reference.
Much like the Debian package tracker, manpages.debian.org includes packages
from Debian oldstable, oldstable-backports, stable, stable-backports, testing
and unstable. New manpages should make their way onto manpages.debian.org
within a few hours.
The generator program ( debiman ) is open source and can be found at https://github.com/Debian/debiman.
In case you would like to use it to run a similar manpage repository (or
convert your existing manpage repository to it), we d love to help you out;
just send an email to stapelberg AT debian DOT org.
This effort is standing on the shoulders of giants: check out https://manpages.debian.org/about.html
for a list of people we thank.
We d love to hear your feedback and thoughts. Either contact us via an
issue on https://github.com/Debian/debiman/issues/,
or send an email to the debian-doc mailing list (see https://lists.debian.org/debian-doc/).
Personally, I find the packaging tools which are available in Debian
far too complex. To better understand the options we have, I
created a diagram of tools which are frequently used, only covering the build
step (i.e. no post-build quality assurance checks or packaging-time helpers):
When I was first introduced to Debian packaging, people recommended I use
pbuilder. Given how complex the toolchain is in the pbuilder case,
I don t understand why that is (was?) a common recommendation.
Back in August 2015, so well over a year ago, I switched to
sbuild, motivated by how much simpler it was to implement ratt
(rebuilds reverse build dependencies) using sbuild, and I have not looked
back.
Are there people who do not use sbuild for reasons other than familiarity? If
so, please let me know, I d like to understand.
I also made a version of the diagram above, colored by the programming
languages in which the tools are implemented. The chosen colors are heavily
biased :-).
To me, the diagram above means: if you want to make substantial changes to the
Debian build tool infrastructure, you need to become an expert in all of
Python, Perl, Bash, C and Make. I know that this is not true for every change,
but it still irks me that there might be changes for which it is required.
I propose to eliminate complexity in Debian by deprecating the pbuilder
toolchain in favor of sbuild.
The last couple of days, I worked on getting Debian to run on the Raspberry Pi
3.
Thanks to the work of many talented people, the Linux kernel in version 4.8 is
_almost_ ready to run on the Raspberry Pi 3. The only missing thing is the
bcm2835 MMC driver, which is required to read the root file system from the SD
card. I ve asked our maintainers to include the
patch for the time being.
Aside from the kernel, one also needs a working bootloader, hence I used
Ubuntu s linux-firmware-raspi2 package and uploaded the linux-firmware-raspi3
package to Debian. The package is currently in the NEW queue and needs to
be accepted by ftp-master before entering Debian.
The most popular method of providing a Linux distribution for the Raspberry Pi
is to provide an image that can be written to an SD card. I made two little
changes to vmdebootstrap (#845439, #845526)
which make it easier to create such an image.
The Debian wiki page https://wiki.debian.org/RaspberryPi3
describes the current state of affairs and should be updated, as this blog post
will not be updated.
As a preview version (i.e. unofficial, unsupported, etc.)
until all the necessary bits and pieces are in place to build images in a
proper place in Debian, I built and uploaded the resulting image. Find it at https://people.debian.org/~stapelberg/raspberrypi3/.
To install the image, insert the SD card into your computer (I m assuming it s
available as /dev/sdb) and copy the image onto it:
I hope this initial work on getting Debian booted will motivate other people to
contribute little improvements here and there. A list of current limitations
and potential improvements can be found on the RaspberryPi3 Debian wiki page.
What happened in the Reproducible
Builds effort between Sunday September 25 and Saturday October 1 2016:
Statistics
For the first time, we reached 91% reproducible packages in our testing framework on
testing/amd64 using a determistic build path. (This is what we recommend to make packages in Stretch reproducible.)
For unstable/amd64, where we additionally test for reproducibility across
different build paths we are at almost 76% again.
IRC meetings
We have a poll to set a time for a new regular IRC meeting.
If you would like to attend, please input your available times and we will try
to accommodate for you.
There was a trial IRC meeting on Friday, 2016-09-31 1800 UTC. Unfortunately, we
did not activate meetbot.
Despite this participants consider the meeting a success as several topics where
discussed (eg changes to IRC notifications of tests.r-b.o) and the meeting stayed
within one our length.
Upcoming events
Reproduce and Verify Filesystems
- Vincent Batts, Red Hat - Berlin (Germany), 5th October, 14:30 - 15:20 @
LinuxCon + ContainerCon Europe 2016.
From Reproducible Debian builds to Reproducible OpenWrt, LEDE &
coreboot - Holger "h01ger" Levsen and
Alexander "lynxis" Couzens - Berlin (Germany), 13th October, 11:00 - 11:25 @
OpenWrt Summit 2016.
Introduction to Reproducible
Builds
- Vagrant Cascadian will be presenting at the SeaGL.org Conference In
Seattle (USA), November 11th-12th, 2016.
Previous events
GHC Determinism
- Bartosz Nitka, Facebook - Nara (Japan), 24th September, ICPF 2016.
Toolchain development and fixes
Michael Meskes uploaded bsdmainutils/9.0.11 to unstable with a fix
for #830259 based on Reiner Herrmann's patch. This fixed locale_dependent_symbol_order_by_lorder issue in the affected packages (freebsd-libs, mmh).
devscripts/2.16.8 was uploaded to unstable. It includes a debrepro
script by Antonio Terceiro which is similar in purpose to reprotest but more
lightweight; specific to Debian packages and without support for virtual servers
or configurable variations.
Packages reviewed and fixed, and bugs filed
The following updated packages have become reproducible in our testing framework
after being fixed:
The following updated packages appear to be reproducible now for reasons we
were not able to figure out. (Relevant changelogs did not mention reproducible
builds.)
Reviews of unreproducible packages
77 package reviews have been added, 178 have been updated and 80 have been
removed in this week, adding to our knowledge about identified
issues.
6 issue types have been updated:
Weekly QA work
As part of reproducibility testing, FTBFS bugs have been detected and reported
by:
Adrian Bunk (3)
Chris Lamb (12)
Lucas Nussbaum (3)
Sebastian Reichel (1)
diffoscope development
A new version of diffoscope 61 was
uploaded to unstable by Chris
Lamb. It included
contributions
from:
Ximin Luo:
Improve the CLI --help text and add an --output-empty option.
Chris Lamb:
Add a progress bar and show it if stdout is a TTY. You can read more about
it here. It can
also be read by higher-level programs via the --status-fd CLI option.
Maria Glukhova:
Behaviour improvements in the case of OS-level errors.
Mattia Rizzolo:
Testing and packaging improvements.
Post-release there were further contributions from:
Chris Lamb:
Code architecture improvements.
Maria Glukhova:
Testing improvements.
reprotest development
A new version of reprotest 0.3.2 was
uploaded to unstable by Ximin
Luo. It included
contributions
from:
Ximin Luo:
Add a --diffoscope-arg CLI option to pass extra args to diffoscope.
Post-release there were further contributions from:
Chris Lamb:
Code quality improvements.
tests.reproducible-builds.org
Hans-Christoph Steiner continued work on setting up reproducible tests for F-Droid.
Holger cleaned up the script creating the page showing breakages, so that it now also cleans up some of the breakage it finds.
IRC notifications about diffoscope crashes and artifacts available for investigations have been dropped; instead the breakages page has a permanent pointer. (h01ger)
IRC notifications from the automatic package scheduler and status changes for packages have been moved -- as a temporary trial -- to #debian-reproducible-changes on irc.oftc.net (Mattia).
Misc.
This week's edition was written by Ximin Luo, Holger Levsen & Chris Lamb and reviewed by a bunch of Reproducible Builds folks on IRC.
A while ago, it occurred to me that querying Debian Code Search seemed slow, which surprised me because I previously spent quite some effort on making it faster, see Debian Code Search Instant and Taming the latency tail for the most recent substantial architecture overhaul and related optimizations.
Upon taking a closer look, I realized that while performing the search query on the server side was pretty fast, the perceived slowness was due to the client side being slow. By being slow , I mean that it took a long time until something was drawn on the screen (high latency) and that what was happening on the screen was janky (stuttering, not smooth).
Part of that slowness was due to historical reasons: the client-side architecture was optimized for the use-case where users open Debian Code Search s index page and then submit a search query, but I was using Chrome s address bar to send a search query (type codesearch , then hit the TAB key). Further, we only added a non-JavaScript version after we launched the JavaScript version. Hence, the redirects and progressive enhancements we implemented are more of a kludge than a well thought out design.
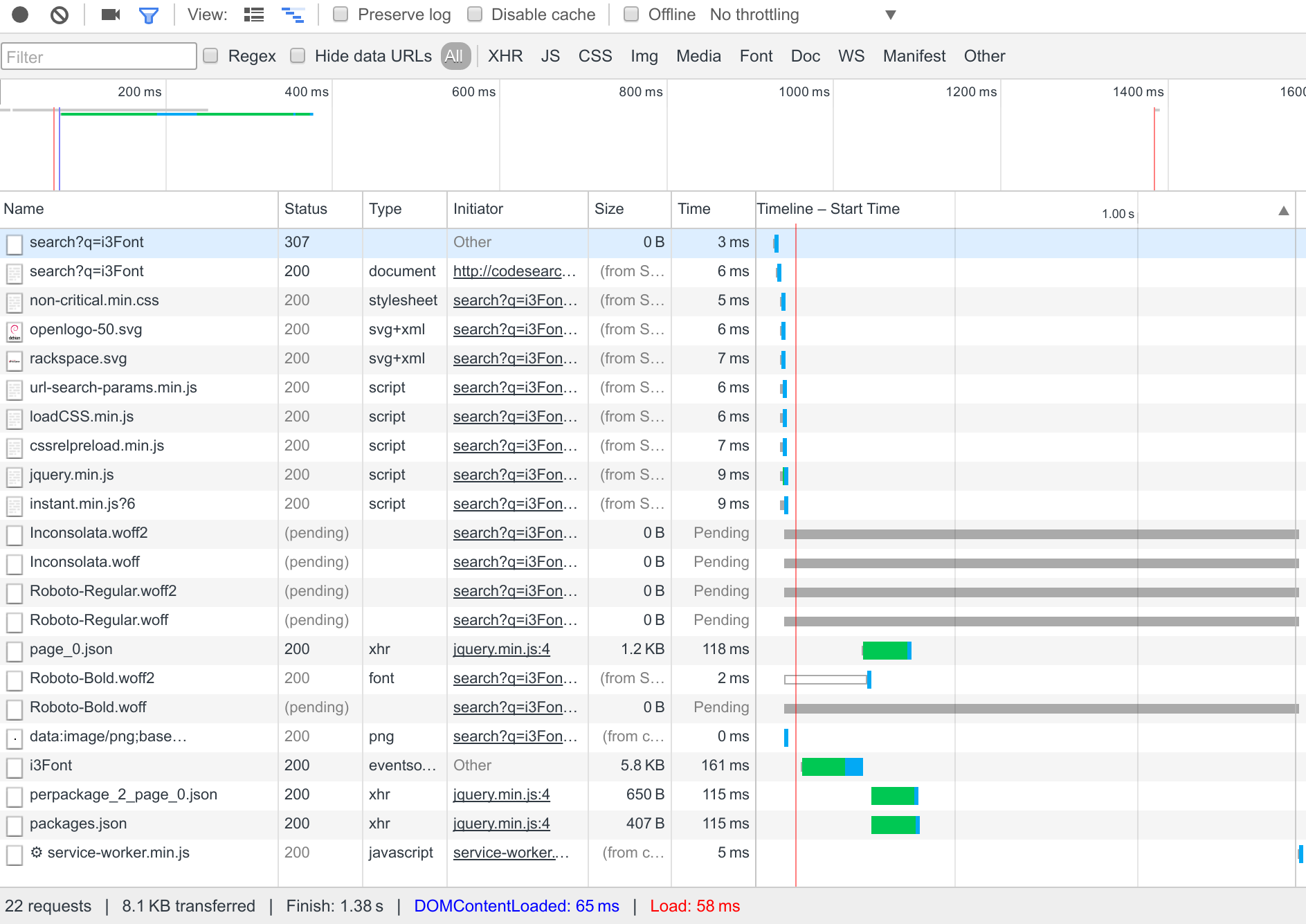
After this bit of original investigation, I opened GitHub issue #69 to track the work on making Debian Code Search faster. In that issue, I captured how Chrome s network inspector visualizes the work necessary to render the page:
A couple of quick wins
There are a couple of little fixes and improvements on which I m not going to spend too much time on, but which I list for completeness anyway just in case they come in handy for a similar project of yours:
Bigger changes
The URL pattern has changed. Previously, we had 2 areas of the website, one for JavaScript-compatible clients and one for the rest. When you hit the wrong one, you were redirected. In some areas, we couldn t tell which area is the correct one for you, so you would always incur a redirect: one example for this is the search bar. With the new URL pattern, we deliver both versions under the same URL: the elements only used by the JavaScript code are hidden using CSS by default, then made visible by JavaScript code. The elements only used by the non-JavaScript code are wrapped in a <noscript> tag.
All CSS which is required for the initial page rendering is now inlined in the responses, allowing the browser to immediately render a response without requiring any additional round trips.
All non-essential CSS has been moved into a separate CSS file which is loaded asynchronously. This is done using a pattern like <link rel="preload" href="foo.css" as="style" onload="this.rel='stylesheet'">, see also filamentgroup/loadCSS.
We switched from WebSockets to the EventSource API because the former is not compatible with HTTP/2, whereas the latter is. This removes a round trip and some custom code for WebSocket reconnecting, because EventSource does that for you.
The progress bar animation used to animate the background-position property. It turns out that browsers can only animate the position, scale, rotation and opacity properties smoothly, because such animations can be off-loaded to the GPU. Hence, we have re-implemented the progress bar animation using the position property.
The biggest win for improving client-side latency from the Chrome address bar was introducing Service Workers (see commit 7f31aef402cb782056e290a797f224171f4af270). Our Service Worker caches static assets and a placeholder results page. The placeholder page is presented immediately when you start a search (e.g. from the address bar), making the first response immediate, i.e. rendered within 100ms. Having assets and the result page out of the way, the first round trip is used for actually doing the search, removing all unnecessary overhead.
With all of these improvements in place, rendering latency goes down from half a second to well under 100 ms, and this is what the Chrome network inspector looks like:
Recently, I was wondering why I was pushing off accepting contributions in Debian for longer than in other projects. It occurred to me that the effort to accept a contribution in Debian is way higher than in other FOSS projects. My remaining FOSS projects are on GitHub, where I can just click the Merge button after deciding a contribution looks good. In Debian, merging is actually a lot of work: I need to clone the repository, configure it, merge the patch, update the changelog, build and upload.
I wondered how close we can bring Debian to a model where accepting a contribution is just a single click as well. In principle, I think it can be done.
To demonstrate the feasibility and collect some feedback, I wrote a program called mergebot. The first stage is done: mergebot can be used on your local machine as a command-line tool. You provide it with the source package and bug number which contains the patch in question, and it will do the rest:
midna~ $ mergebot -source_package=wit -bug=#831331
2016/07/17 12:06:06 will work on package "wit", bug "831331"
2016/07/17 12:06:07 Skipping MIME part with invalid Content-Disposition header (mime: no media type)
2016/07/17 12:06:07 gbp clone --pristine-tar git+ssh://git.debian.org/git/collab-maint/wit.git /tmp/mergebot-743062986/repo
2016/07/17 12:06:09 git config push.default matching
2016/07/17 12:06:09 git config --add remote.origin.push +refs/heads/*:refs/heads/*
2016/07/17 12:06:09 git config --add remote.origin.push +refs/tags/*:refs/tags/*
2016/07/17 12:06:09 git config user.email stapelberg AT debian DOT org
2016/07/17 12:06:09 patch -p1 -i ../latest.patch
2016/07/17 12:06:09 git add .
2016/07/17 12:06:09 git commit -a --author Chris Lamb <lamby AT debian DOT org> --message Fix for wit: please make the build reproducible (Closes: #831331)
2016/07/17 12:06:09 gbp dch --release --git-author --commit
2016/07/17 12:06:09 gbp buildpackage --git-tag --git-export-dir=../export --git-builder=sbuild -v -As --dist=unstable
2016/07/17 12:07:16 Merge and build successful!
2016/07/17 12:07:16 Please introspect the resulting Debian package and git repository, then push and upload:
2016/07/17 12:07:16 cd "/tmp/mergebot-743062986"
2016/07/17 12:07:16 (cd repo && git push)
2016/07/17 12:07:16 (cd export && debsign *.changes && dput *.changes)
midna~ $ cd /tmp/mergebot-743062986/repo
midna/tmp/mergebot-743062986/repo $ git log HEAD~2..
commit d983d242ee546b2249a866afe664bac002a06859
Author: Michael Stapelberg <stapelberg AT debian DOT org>
Date: Sun Jul 17 13:32:41 2016 +0200
Update changelog for 2.31a-3 release
commit 5a327f5d66e924afc656ad71d3bfb242a9bd6ddc
Author: Chris Lamb <lamby AT debian DOT org>
Date: Sun Jul 17 13:32:41 2016 +0200
Fix for wit: please make the build reproducible (Closes: #831331)
midna/tmp/mergebot-743062986/repo $ git push
Counting objects: 11, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (11/11), done.
Writing objects: 100% (11/11), 1.59 KiB 0 bytes/s, done.
Total 11 (delta 6), reused 0 (delta 0)
remote: Sending notification emails to: dispatch+wit_vcs@tracker.debian.org
remote: Sending notification emails to: dispatch+wit_vcs@tracker.debian.org
To git+ssh://git.debian.org/git/collab-maint/wit.git
650ee05..d983d24 master -> master
* [new tag] debian/2.31a-3 -> debian/2.31a-3
midna/tmp/mergebot-743062986/repo $ cd ../export
midna/tmp/mergebot-743062986/export $ debsign *.changes && dput *.changes
[ ]
Uploading wit_2.31a-3.dsc
Uploading wit_2.31a-3.debian.tar.xz
Uploading wit_2.31a-3_amd64.deb
Uploading wit_2.31a-3_amd64.changes
Of course, this is not quite as convenient as clicking a Merge button yet. I have some ideas on how to make that happen, but I need to know whether people are interested before I spend more time on this.
Please see github.com/Debian/mergebot for more details, and please get in touch if you think this is worthwhile or would even like to help. Feedback is accepted in the GitHub issue tracker for mergebot or the project mailing list mergebot-discuss. Thanks!
As some of the world knows full well by now, I've been noodling with Go
for a few years, working through its pros, its cons, and thinking a lot
about how humans use code to express thoughts and ideas. Go's got a lot of
neat use cases, suited to particular problems, and used in the right place,
you can see some clear massive wins.
I've started writing Debian tooling in Go, because it's a pretty natural fit.
Go's fairly tight, and overhead shouldn't be taken up by your operating system.
After a while, I wound up hitting the usual blockers, and started to build up
abstractions. They became pretty darn useful, so, this blog post is announcing
(a still incomplete, year old and perhaps API changing) Debian package for Go.
The Go importable name is pault.ag/go/debian. This contains a lot of utilities
for dealing with Debian packages, and will become an edited down "toolbelt"
for working with or on Debian packages.
Module Overview
Currently, the package contains 4 major sub packages. They're a changelog
parser, a control file parser, deb file format parser, dependency parser
and a version parser. Together, these are a set of powerful building blocks
which can be used together to create higher order systems with reliable
understandings of the world.
changelog
The first (and perhaps most incomplete and least tested) is a changelog file
parser.. This provides the
programmer with the ability to pull out the suite being targeted in the
changelog, when each upload was, and the version for each. For example, let's
look at how we can pull when all the uploads of Docker to sid took place:
funcmain()resp,err:=http.Get("http://metadata.ftp-master.debian.org/changelogs/main/d/docker.io/unstable_changelog")iferr!=nilpanic(err)allEntries,err:=changelog.Parse(resp.Body)iferr!=nilpanic(err)for_,entry:=rangeallEntriesfmt.Printf("Version %s was uploaded on %s\n",entry.Version,entry.When)
The output of which looks like:
Version 1.8.3~ds1-2 was uploaded on 2015-11-04 00:09:02 -0800 -0800
Version 1.8.3~ds1-1 was uploaded on 2015-10-29 19:40:51 -0700 -0700
Version 1.8.2~ds1-2 was uploaded on 2015-10-29 07:23:10 -0700 -0700
Version 1.8.2~ds1-1 was uploaded on 2015-10-28 14:21:00 -0700 -0700
Version 1.7.1~dfsg1-1 was uploaded on 2015-08-26 10:13:48 -0700 -0700
Version 1.6.2~dfsg1-2 was uploaded on 2015-07-01 07:45:19 -0600 -0600
Version 1.6.2~dfsg1-1 was uploaded on 2015-05-21 00:47:43 -0600 -0600
Version 1.6.1+dfsg1-2 was uploaded on 2015-05-10 13:02:54 -0400 EDT
Version 1.6.1+dfsg1-1 was uploaded on 2015-05-08 17:57:10 -0600 -0600
Version 1.6.0+dfsg1-1 was uploaded on 2015-05-05 15:10:49 -0600 -0600
Version 1.6.0+dfsg1-1~exp1 was uploaded on 2015-04-16 18:00:21 -0600 -0600
Version 1.6.0~rc7~dfsg1-1~exp1 was uploaded on 2015-04-15 19:35:46 -0600 -0600
Version 1.6.0~rc4~dfsg1-1 was uploaded on 2015-04-06 17:11:33 -0600 -0600
Version 1.5.0~dfsg1-1 was uploaded on 2015-03-10 22:58:49 -0600 -0600
Version 1.3.3~dfsg1-2 was uploaded on 2015-01-03 00:11:47 -0700 -0700
Version 1.3.3~dfsg1-1 was uploaded on 2014-12-18 21:54:12 -0700 -0700
Version 1.3.2~dfsg1-1 was uploaded on 2014-11-24 19:14:28 -0500 EST
Version 1.3.1~dfsg1-2 was uploaded on 2014-11-07 13:11:34 -0700 -0700
Version 1.3.1~dfsg1-1 was uploaded on 2014-11-03 08:26:29 -0700 -0700
Version 1.3.0~dfsg1-1 was uploaded on 2014-10-17 00:56:07 -0600 -0600
Version 1.2.0~dfsg1-2 was uploaded on 2014-10-09 00:08:11 +0000 +0000
Version 1.2.0~dfsg1-1 was uploaded on 2014-09-13 11:43:17 -0600 -0600
Version 1.0.0~dfsg1-1 was uploaded on 2014-06-13 21:04:53 -0400 EDT
Version 0.11.1~dfsg1-1 was uploaded on 2014-05-09 17:30:45 -0400 EDT
Version 0.9.1~dfsg1-2 was uploaded on 2014-04-08 23:19:08 -0400 EDT
Version 0.9.1~dfsg1-1 was uploaded on 2014-04-03 21:38:30 -0400 EDT
Version 0.9.0+dfsg1-1 was uploaded on 2014-03-11 22:24:31 -0400 EDT
Version 0.8.1+dfsg1-1 was uploaded on 2014-02-25 20:56:31 -0500 EST
Version 0.8.0+dfsg1-2 was uploaded on 2014-02-15 17:51:58 -0500 EST
Version 0.8.0+dfsg1-1 was uploaded on 2014-02-10 20:41:10 -0500 EST
Version 0.7.6+dfsg1-1 was uploaded on 2014-01-22 22:50:47 -0500 EST
Version 0.7.1+dfsg1-1 was uploaded on 2014-01-15 20:22:34 -0500 EST
Version 0.6.7+dfsg1-3 was uploaded on 2014-01-09 20:10:20 -0500 EST
Version 0.6.7+dfsg1-2 was uploaded on 2014-01-08 19:14:02 -0500 EST
Version 0.6.7+dfsg1-1 was uploaded on 2014-01-07 21:06:10 -0500 EST
control
Next is one of the most complex, and one of the oldest parts of go-debian,
which is the control file parser
(otherwise sometimes known as deb822). This module was inspired by the way
that the json module works in Go, allowing for files to be defined in code
with a struct. This tends to be a bit more declarative, but also winds up
putting logic into struct tags, which can be a nasty anti-pattern if used too
much.
The first primitive in this module is the concept of a Paragraph, a struct
containing two values, the order of keys seen, and a map of string to string.
All higher order functions dealing with control files will go through this
type, which is a helpful interchange format to be aware of. All parsing of
meaning from the Control file happens when the Paragraph is unpacked into
a struct using reflection.
The idea behind this strategy that you define your struct, and let the Control
parser handle unpacking the data from the IO into your container, letting you
maintain type safety, since you never have to read and cast, the conversion
will handle this, and return an Unmarshaling error in the event of failure.
Additionally, Structs that define an anonymous member of control.Paragraph
will have the raw Paragraph struct of the underlying file, allowing the
programmer to handle dynamic tags (such as X-Foo), or at least, letting
them survive the round-trip through go.
The default decoder
contains an argument, the ability to verify the input control file using an
OpenPGP keyring, which is exposed to the programmer through the
(*Decoder).Signer() function. If the passed argument is nil, it will not
check the input file signature (at all!), and if it has been passed, any
signed data must be found or an error will fall out of the NewDecoder call.
On the way out, the opposite happens, where the struct is introspected,
turned into a control.Paragraph, and then written out to the io.Writer.
Here's a quick (and VERY dirty) example showing the basics of reading and
writing Debian Control files with go-debian.
packagemainimport("fmt""io""net/http""strings""pault.ag/go/debian/control")typeAllowedPackagestructPackagestringFingerprintstringfunc(a*AllowedPackage)UnmarshalControl(instring)errorin=strings.TrimSpace(in)chunks:=strings.SplitN(in," ",2)iflen(chunks)!=2returnfmt.Errorf("Syntax sucks: '%s'",in)a.Package=chunks[0]a.Fingerprint=chunks[1][1:len(chunks[1])-1]returnniltypeDMUAstructFingerprintstringUidstringAllowedPackages[]AllowedPackage control:"Allow" delim:"," funcmain()resp,err:=http.Get("http://metadata.ftp-master.debian.org/dm.txt")iferr!=nilpanic(err)decoder,err:=control.NewDecoder(resp.Body,nil)iferr!=nilpanic(err)fordmua:=DMUAiferr:=decoder.Decode(&dmua);err!=niliferr==io.EOFbreakpanic(err)fmt.Printf("The DM %s is allowed to upload:\n",dmua.Uid)for_,allowedPackage:=rangedmua.AllowedPackagesfmt.Printf(" %s [granted by %s]\n",allowedPackage.Package,allowedPackage.Fingerprint)
Output (truncated!) looks a bit like:
...
The DM Allison Randal <allison@lohutok.net> is allowed to upload:
parrot [granted by A4F455C3414B10563FCC9244AFA51BD6CDE573CB]
...
The DM Benjamin Barenblat <bbaren@mit.edu> is allowed to upload:
boogie [granted by 3224C4469D7DF8F3D6F41A02BBC756DDBE595F6B]
dafny [granted by 3224C4469D7DF8F3D6F41A02BBC756DDBE595F6B]
transmission-remote-gtk [granted by 3224C4469D7DF8F3D6F41A02BBC756DDBE595F6B]
urweb [granted by 3224C4469D7DF8F3D6F41A02BBC756DDBE595F6B]
...
The DM <aelmahmoudy@sabily.org> is allowed to upload:
covered [granted by 41352A3B4726ACC590940097F0A98A4C4CD6E3D2]
dico [granted by 6ADD5093AC6D1072C9129000B1CCD97290267086]
drawtiming [granted by 41352A3B4726ACC590940097F0A98A4C4CD6E3D2]
fonts-hosny-amiri [granted by BD838A2BAAF9E3408BD9646833BE1A0A8C2ED8FF]
...
...
deb
Next up, we've got the deb module. This contains code to handle reading
Debian 2.0 .deb files. It contains a wrapper that will parse the control
member, and provide the data member through the
archive/tar interface.
Here's an example of how to read a .deb file, access some metadata, and
iterate over the tar archive, and print the filenames of each of the
entries.
dependency
The dependency package provides an interface to parse and compute
dependencies. This package is a bit odd in that, well, there's no other
library that does this. The issue is that there are actually two different
parsers that compute our Dependency lines, one in Perl (as part of dpkg-dev)
and another in C (in dpkg).
To date, this has resulted in me filing
threedifferentbugs.
I also found a broken package in the
archive,
which actually resulted in another bug being (totally accidentally)
already fixed.
I hope to continue to run the archive through my parser in hopes of finding
more bugs! This package is a bit complex, but it basically just returns what
amounts to be an AST
for our Dependency lines. I'm positive there are bugs, so file them!
funcmain()dep,err:=dependency.Parse("foo bar, baz, foobar [amd64] bazfoo [!sparc], fnord:armhf [gnu-linux-sparc]")iferr!=nilpanic(err)anySparc,err:=dependency.ParseArch("sparc")iferr!=nilpanic(err)for_,possi:=rangedep.GetPossibilities(*anySparc)fmt.Printf("%s (%s)\n",possi.Name,possi.Arch)
Gives the output:
foo (<nil>)
baz (<nil>)
fnord (armhf)
version
Right off the bat, I'd like to thank
Michael Stapelberg for letting me graft this
out of dcs and into the go-debian package.
This was nearly entirely his work (with a one or two line function I added
later), and was amazingly helpful to have. Thank you!
This module implements Debian version comparisons and parsing, allowing for
sorting in lists, checking to see if it's native or not, and letting the
programmer to implement smart(er!) logic based on upstream (or Debian)
version numbers.
This module is extremely easy to use and very straightforward, and not worth
writing an example for.
Final thoughts
This is more of a "Yeah, OK, this has been useful enough to me at this point
that I'm going to support this" rather than a "It's stable!" or even
"It's alive!" post. Hopefully folks can report bugs and help iterate on
this module until we have some really clean building blocks to build
solid higher level systems on top of. Being able to have multiple libraries
interoperate by relying on go-debian will be a massive ease.
I'm in need of more documentation, and to finalize some parts of the older
sub package APIs, but I'm hoping to be at a "1.0" real soon now.
When uploading a new library package which changes its API/behavior in a subtle
way, typically you will only hear about the downstream breakage after you ve
uploaded the new library package (via bug reports telling you that your package
FTBFS, fails to build from source).
I prefer quality-assurance to happen proactively rather than reactively
whenever possible, so I set out to write a tool which automates the rebuild of
reverse-build-dependencies, i.e. all packages whose build process could be
affected by the package one is about to upload.
The result is a tool called ratt,
which is short for Rebuild All The Things! . It injects the newly-built Debian
package you provide it, figures out all the reverse-build-dependencies, invokes
sbuild for all of them, and finally presents you with a list of packages that
failed to build.
To demonstrate how the tool works, let s assume we want to upload a new version of the
Go library github.com/jacobsa/gcloud. To keep
this example brief, we don t actually do anything to the package but bump its
version number:
Thanks for reading this far, and I hope ratt makes your life a tiny
bit easier. As ratt just
entered Debian unstable, you can install it using apt-get install
ratt. If you have any feedback, I m eager to hear it.
So we had 10 packages fixed and uploaded by 10 different uploaders. A big "Thank You" to you!!
Since the start of this challenge, a total of 59 packages, were fixed.
Here is a quick overview:
Week 1
Week 2
Week 3
Week 4
Week 5
Week 6
Week 7
# Packages
10
15
10
14
10
-
-
Total
10
25
35
49
59
-
-
The list of the fixed and updated packages is availabe here. I will try to update this ~daily. If I missed one of your uploads, please drop me a line.
Only 2 more weeks to DebConf15 so please get involved: The DUCK Challenge is running until end of DebConf15!
Pevious articles are here: Week 1, Week 2, Week 3, Week 4.
Recently, the pkg-go team has
been quite busy, uploading dozens of Go library packages in order to be able to
package gcsfuse (a
user-space file system for interacting with Google Cloud Storage) and InfluxDB (an open-source distributed time
series database).
Packaging Go library packages (!) is a fairly repetitive process, so before
starting my work on the dependencies for gcsfuse, I started writing a tool
called dh-make-golang.
Just like dh-make itself, the goal is to automatically create (almost) an
entire Debian package.
As I worked my way through the dependencies of gcsfuse, I refined how the tool
works, and now I believe it s good enough for a first release.
To demonstrate how the tool works, let s assume we want to package the Go
library github.com/jacobsa/ratelimit:
midna/tmp $ dh-make-golang github.com/jacobsa/ratelimit
2015/07/25 18:25:39 Downloading "github.com/jacobsa/ratelimit/..."
2015/07/25 18:25:53 Determining upstream version number
2015/07/25 18:25:53 Package version is "0.0~git20150723.0.2ca5e0c"
2015/07/25 18:25:53 Determining dependencies
2015/07/25 18:25:55
2015/07/25 18:25:55 Packaging successfully created in /tmp/golang-github-jacobsa-ratelimit
2015/07/25 18:25:55
2015/07/25 18:25:55 Resolve all TODOs in itp-golang-github-jacobsa-ratelimit.txt, then email it out:
2015/07/25 18:25:55 sendmail -t -f < itp-golang-github-jacobsa-ratelimit.txt
2015/07/25 18:25:55
2015/07/25 18:25:55 Resolve all the TODOs in debian/, find them using:
2015/07/25 18:25:55 grep -r TODO debian
2015/07/25 18:25:55
2015/07/25 18:25:55 To build the package, commit the packaging and use gbp buildpackage:
2015/07/25 18:25:55 git add debian && git commit -a -m 'Initial packaging'
2015/07/25 18:25:55 gbp buildpackage --git-pbuilder
2015/07/25 18:25:55
2015/07/25 18:25:55 To create the packaging git repository on alioth, use:
2015/07/25 18:25:55 ssh git.debian.org "/git/pkg-go/setup-repository golang-github-jacobsa-ratelimit 'Packaging for golang-github-jacobsa-ratelimit'"
2015/07/25 18:25:55
2015/07/25 18:25:55 Once you are happy with your packaging, push it to alioth using:
2015/07/25 18:25:55 git push git+ssh://git.debian.org/git/pkg-go/packages/golang-github-jacobsa-ratelimit.git --tags master pristine-tar upstream
The ITP is often the most labor-intensive part of the packaging process,
because any number of auto-detected values might be wrong: the repository owner
might not be the Upstream Author , the repository might not have a short
description, the long description might need some adjustments or the license
might not be auto-detected.
midna/tmp $ cat itp-golang-github-jacobsa-ratelimit.txt
From: "Michael Stapelberg" <stapelberg AT debian.org>
To: submit@bugs.debian.org
Subject: ITP: golang-github-jacobsa-ratelimit -- Go package for rate limiting
Content-Type: text/plain; charset=utf-8
Content-Transfer-Encoding: 8bit
Package: wnpp
Severity: wishlist
Owner: Michael Stapelberg <stapelberg AT debian.org>
* Package name : golang-github-jacobsa-ratelimit
Version : 0.0~git20150723.0.2ca5e0c-1
Upstream Author : Aaron Jacobs
* URL : https://github.com/jacobsa/ratelimit
* License : Apache-2.0
Programming Lang: Go
Description : Go package for rate limiting
GoDoc (https://godoc.org/github.com/jacobsa/ratelimit)
.
This package contains code for dealing with rate limiting. See the
reference (http://godoc.org/github.com/jacobsa/ratelimit) for more info.
TODO: perhaps reasoning
midna/tmp $
After filling in all the TODOs in the file, let s mail it out and get a sense
of what else still needs to be done:
After filling in these TODOs as well, let s have a final look at what we re
about to build:
midna/tmp/golang-github-jacobsa-ratelimitmaster $ head -100 debian/**/*
==> debian/changelog <==
golang-github-jacobsa-ratelimit (0.0~git20150723.0.2ca5e0c-1) unstable; urgency=medium
* Initial release (Closes: #793646)
-- Michael Stapelberg <stapelberg@debian.org> Sat, 25 Jul 2015 23:26:34 +0200
==> debian/compat <==
9
==> debian/control <==
Source: golang-github-jacobsa-ratelimit
Section: devel
Priority: extra
Maintainer: pkg-go <pkg-go-maintainers@lists.alioth.debian.org>
Uploaders: Michael Stapelberg <stapelberg@debian.org>
Build-Depends: debhelper (>= 9),
dh-golang,
golang-go,
golang-github-jacobsa-gcloud-dev,
golang-github-jacobsa-oglematchers-dev,
golang-github-jacobsa-ogletest-dev,
golang-github-jacobsa-syncutil-dev,
golang-golang-x-net-dev
Standards-Version: 3.9.6
Homepage: https://github.com/jacobsa/ratelimit
Vcs-Browser: http://anonscm.debian.org/gitweb/?p=pkg-go/packages/golang-github-jacobsa-ratelimit.git;a=summary
Vcs-Git: git://anonscm.debian.org/pkg-go/packages/golang-github-jacobsa-ratelimit.git
Package: golang-github-jacobsa-ratelimit-dev
Architecture: all
Depends: $ shlibs:Depends ,
$ misc:Depends ,
golang-go,
golang-github-jacobsa-gcloud-dev,
golang-github-jacobsa-oglematchers-dev,
golang-github-jacobsa-ogletest-dev,
golang-github-jacobsa-syncutil-dev,
golang-golang-x-net-dev
Built-Using: $ misc:Built-Using
Description: Go package for rate limiting
This package contains code for dealing with rate limiting. See the
reference (http://godoc.org/github.com/jacobsa/ratelimit) for more info.
==> debian/copyright <==
Format: http://www.debian.org/doc/packaging-manuals/copyright-format/1.0/
Upstream-Name: ratelimit
Source: https://github.com/jacobsa/ratelimit
Files: *
Copyright: 2015 Aaron Jacobs
License: Apache-2.0
Files: debian/*
Copyright: 2015 Michael Stapelberg <stapelberg@debian.org>
License: Apache-2.0
Comment: Debian packaging is licensed under the same terms as upstream
License: Apache-2.0
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
.
http://www.apache.org/licenses/LICENSE-2.0
.
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
.
On Debian systems, the complete text of the Apache version 2.0 license
can be found in "/usr/share/common-licenses/Apache-2.0".
==> debian/gbp.conf <==
[DEFAULT]
pristine-tar = True
==> debian/rules <==
#!/usr/bin/make -f
export DH_GOPKG := github.com/jacobsa/ratelimit
%:
dh $@ --buildsystem=golang --with=golang
==> debian/source <==
head: error reading debian/source : Is a directory
==> debian/source/format <==
3.0 (quilt)
midna/tmp/golang-github-jacobsa-ratelimitmaster $
Okay, then. Let s give it a shot and see if it builds:
This package just built (as it should!), but occasionally one might need to disable a test and file an upstream bug about it. So, let s push this package to pkg-go and upload it:
midna/tmp/golang-github-jacobsa-ratelimitmaster $ ssh git.debian.org "/git/pkg-go/setup-repository golang-github-jacobsa-ratelimit 'Packaging for golang-github-jacobsa-ratelimit'"
Initialized empty shared Git repository in /srv/git.debian.org/git/pkg-go/packages/golang-github-jacobsa-ratelimit.git/
HEAD is now at ea6b1c5 add mrconfig for dh-make-golang
[master c5be5a1] add mrconfig for golang-github-jacobsa-ratelimit
1 file changed, 3 insertions(+)
To /git/pkg-go/meta.git
ea6b1c5..c5be5a1 master -> master
midna/tmp/golang-github-jacobsa-ratelimitmaster $ git push git+ssh://git.debian.org/git/pkg-go/packages/golang-github-jacobsa-ratelimit.git --tags master pristine-tar upstream
Counting objects: 31, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (25/25), done.
Writing objects: 100% (31/31), 18.38 KiB 0 bytes/s, done.
Total 31 (delta 2), reused 0 (delta 0)
To git+ssh://git.debian.org/git/pkg-go/packages/golang-github-jacobsa-ratelimit.git
* [new branch] master -> master
* [new branch] pristine-tar -> pristine-tar
* [new branch] upstream -> upstream
* [new tag] upstream/0.0_git20150723.0.2ca5e0c -> upstream/0.0_git20150723.0.2ca5e0c
midna/tmp/golang-github-jacobsa-ratelimitmaster $ cd ..
midna/tmp $ debsign golang-github-jacobsa-ratelimit_0.0\~git20150723.0.2ca5e0c-1_amd64.changes
[ ]
midna/tmp $ dput golang-github-jacobsa-ratelimit_0.0\~git20150723.0.2ca5e0c-1_amd64.changes
Uploading golang-github-jacobsa-ratelimit using ftp to ftp-master (host: ftp.upload.debian.org; directory: /pub/UploadQueue/)
[ ]
Uploading golang-github-jacobsa-ratelimit_0.0~git20150723.0.2ca5e0c-1.dsc
Uploading golang-github-jacobsa-ratelimit_0.0~git20150723.0.2ca5e0c.orig.tar.bz2
Uploading golang-github-jacobsa-ratelimit_0.0~git20150723.0.2ca5e0c-1.debian.tar.xz
Uploading golang-github-jacobsa-ratelimit-dev_0.0~git20150723.0.2ca5e0c-1_all.deb
Uploading golang-github-jacobsa-ratelimit_0.0~git20150723.0.2ca5e0c-1_amd64.changes
midna/tmp $ cd golang-github-jacobsa-ratelimit
midna/tmp/golang-github-jacobsa-ratelimitmaster $ git tag debian/0.0_git20150723.0.2ca5e0c-1
midna/tmp/golang-github-jacobsa-ratelimitmaster $ git push git+ssh://git.debian.org/git/pkg-go/packages/golang-github-jacobsa-ratelimit.git --tags master pristine-tar upstream
Total 0 (delta 0), reused 0 (delta 0)
To git+ssh://git.debian.org/git/pkg-go/packages/golang-github-jacobsa-ratelimit.git
* [new tag] debian/0.0_git20150723.0.2ca5e0c-1 -> debian/0.0_git20150723.0.2ca5e0c-1
midna/tmp/golang-github-jacobsa-ratelimitmaster $
Thanks for reading this far, and I hope dh-make-golang makes your life a tiny
bit easier. As dh-make-golang just
entered Debian unstable, you can install it using apt-get install
dh-make-golang. If you have any feedback, I m eager to hear it.
It s been a couple of weeks since I ve launched Debian Code Search Instant,
so people have had the chance to use it for a while and that gives me plenty of
data points to look at :-). For every query, I log the search term itself as
well as the duration the query took to execute. That way, I can easily identify
queries that take a long time and see why that is.
There is a class of queries for which Debian Code Search (DCS) doesn t perform
so well, and that s queries that consist of trigrams which are extremely
common. Whenever DCS receives such a query, it needs to search through a lot of
files. Note that it doesn t really matter if there are plenty of results or not
it s the number of files that potentially contain a result which matters.
One such query is arse (we get a lot of curse words). It consists of only two
trigrams ( ars and rse ), which are extremely common in program source code.
As a couple of examples, the terms parse , sparse , charset and coarse
are all matched by that. As an aside, if you really want to search for just
arse , use word boundaries, i.e. \barse\b , which also makes the query
significantly faster.
Fixing the overloaded frontend
When DCS first received the query, arse would lead to our frontend server
crashing. That was due to (intentionally) unoptimized code we were
aggregating all search results from all 6 source backends in memory, sorted
them, and then wrote them out to disk.
I addressed this in commit d2922fe92 with the following measures:
Instead of keeping the entire result in memory, just write the result to a
temporary file on disk ( unsorted.json ) and store pointers into that file in
memory, i.e. (offset, length) tuples. In order to sort the results, we also
need to store the ranking and the path (to resolve ties and thereby guarantee a
stable result order over multiple search queries). For grouping the results by
source package, we need to keep the package name.
If you think about it, you don t need the entire path in order to break a tie
the hash is enough, as it defines an ordering. That ordering may be different,
but any ordering is good enough for the purpose of merely breaking a tie in a
deterministic way. I m using Go s hash/fnv, the only non-cryptographic
(fast!) hash function that is included in Go s standard library.
Since this was still leading to Out Of Memory errors, I decided to not store a
copy of the package name in each search result, but rather use a pointer into a
string pool containing all package names. The number of source package names is
relatively small, in the order of 20,000, whereas the number of search results
can be in the millions. Using the stringpool is a clear win the overhead in
the case where #results < #srcpackages is negligible, but as soon as
#results > #srcpackages, you save memory.
With all of that fixed, the query became at all possible, albeit with a runtime
of around 20 minutes.
Double Writing
When running such a long-running query, I noticed that the query ran smooth for
a while, but then it took multiple seconds without any visible progress at the
end of the query before the results appeared. This was due to the frontend
ranking the results and then converting unsorted.json into actual result
pages. Since we provide results ordered by ranking, but also results grouped by
source packages, it was writing every result twice to disk. What s even worse
is that due to re-ordering, every read was essentially random (as opposed to
sequential reads).
What s even worse is that nobody will ever click through all the hundreds of
thousands of result pages, so they are prepared entirely in vain. Therefore,
with commit
c744b236e I made the frontend generate these result pages on demand. This
cut down the time for the ranking phase at the end of each query from 20-30
seconds (for big queries) to typically less than one second.
Profiling/Monitoring
After adding monitoring to each of the source-backends, I realized that during
these long-running queries, the disk I/O and network I/O was nowhere near my
expectations: each source-backend was sending only a low single-digit number of
megabytes per second back to the frontend (typically somewhere between 1 MB/s
and 3 MB/s). This didn t match up at all with the bandwidth I observed in
earlier performance tests, so I used wget -O /dev/null to send a
query and discard the result in order to get some theoretical performance
numbers. Suddenly, I was getting more than 10 MB/s worth of results, maxing
out the disks with a read rate of about 200 MB/s.
So where is the bottleneck? I double-checked that neither the CPU on any of our
VMs, nor the network between them was saturated. Note that as of this point,
the CPU of the frontend was at roughly 70% (of one core), which didn t seem a
lot to me. Then, I followed this excellent tutorial on
profiling Go programs to see where the frontend is spending its time. Turns
out, the biggest consumer of CPU time was the encoding/json Go package, which
is used for deserializing results received from the backend and serializing
them again before sending them to the client.
Since I was curious about it for a while already, I decided to give cap n proto a try to replace
JSON as serialization mechanism for communication between the source backends
and the frontend. Switching
to it (commit 8efd3b41) brought down the CPU load immensely, and made the
query a bit faster. In addition, I killed the next biggest consumer: the
lseek(2) syscall, which we used to call with SEEK_CUR
and an offset of 0 so that it would tell us the current position. This was
necessary in the first place because we don t know in advance how many bytes
we re going to write when serializing a result to disk. The replacement is a
neat little trick:
type countingWriter int64
func (c *countingWriter) Write(p []byte) (n int, err error)
*c += countingWriter(len(p))
return len(p), nil
// [ ]
// Then, use an io.MultiWriter like this:
var written countingWriter
w := io.MultiWriter(s.tempFiles[backendidx], &written)
result.WriteJSON(w)
With some more profiling, the new bottleneck was suddenly the
read(2) syscall, issued by the cap n proto deserialization,
operating directly on the network connection buffer. strace
revealed that crunching through the results of one source backend for a long
query, read(2) was called about 250,000 times. By simply using
a buffered reader (commit 684467ae), I could reduce that to about 2,000
times.
Another bottleneck was the fact that for every processed result, the frontend
needed to update the query state, which is shared amongst all goroutines (there
is one goroutine for each source backend). All that parallelism isn t very
effective if you need to synchronize the state updates in the end. So with commit
5d46a572, I refactored the state to be per-backend, so that locking is only
necessary for the first couple of results, and the vast vast majority of
results can be processed entirely without locking.
This brought down the query time from 20 minutes to about 5 minutes, but I
still wasn t happy with the bandwidth: the frontend was doing a bit over
10 MB/s of reads from all source backends combined, whereas with
wget I could get around 40 MB/s with the same query. At this
point, the CPU utilization was around 7% of one core on the frontend, and
profiling didn t immediately reveal an obvious culprit.
After a bit of experimenting (by commenting out code here and there ;-)), I
figured out that the problem was that the frontend was still converting these
results from capnproto buffers to JSON. While that doesn t take a lot of CPU
time, it delays the network stream from the source-backend: once the local and
remote TCP buffers are full, the source-backend will (intentionally!) not
continue with its search, so that it doesn t run out of memory. I m still
convinced that s a good idea, and in fact I was able to solve the problem in an
elegant way: instead of writing JSON to disk and generating result pages on
demand, we now write
capnproto directly to disk (commit 466b7f3e) and convert it to JSON only
before sending out the result pages. That decreases the overall CPU time since
we only need to convert a small fraction of the results to JSON, but most
importantly, the frontend is now not in the critical path anymore. It can
directly pass the data through, and in fact it uses an
io.TeeReader to do exactly that.
Conclusion
With all of these optimizations, we re now down to about 2.5 minutes for the
search query arse , and the architecture of the system actually got simpler to
reason about.
Most importantly, though, the optimizations don t only play out for a single
query, but for many different queries. I ve deployed the optimized version at
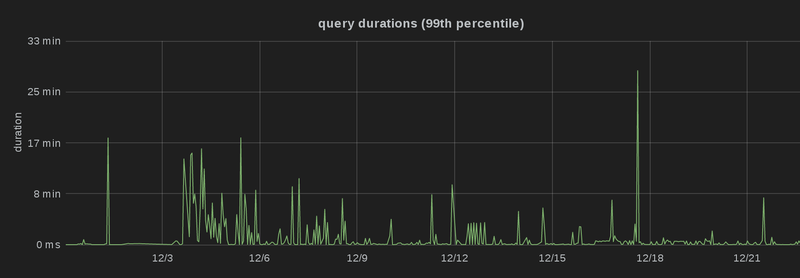
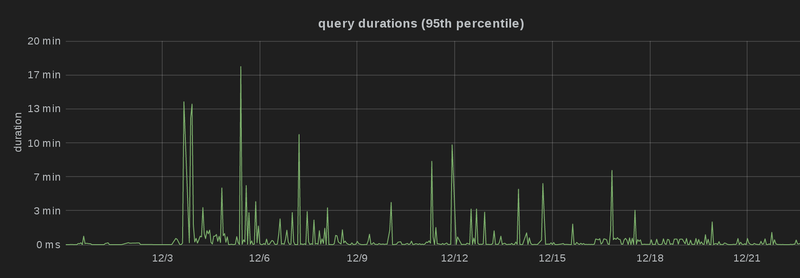
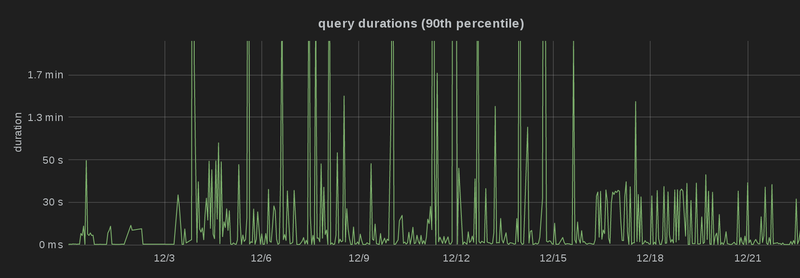
the 15th of December 2014, and you can see that the 99th, 95th and 90th
percentile latency
dropped significantly, i.e. there are a lot fewer spikes than before, and more
queries are processed faster, which is particularly obvious in the third graph
(which is capped at 2 minutes):
 Back in November,
Back in November, 



 A couple of quick wins
There are a couple of little fixes and improvements on which I m not going to spend too much time on, but which I list for completeness anyway just in case they come in handy for a similar project of yours:
A couple of quick wins
There are a couple of little fixes and improvements on which I m not going to spend too much time on, but which I list for completeness anyway just in case they come in handy for a similar project of yours:
 As some of the world knows full well by now, I've been noodling with Go
for a few years, working through its pros, its cons, and thinking a lot
about how humans use code to express thoughts and ideas. Go's got a lot of
neat use cases, suited to particular problems, and used in the right place,
you can see some clear massive wins.
I've started writing Debian tooling in Go, because it's a pretty natural fit.
Go's fairly tight, and overhead shouldn't be taken up by your operating system.
After a while, I wound up hitting the usual blockers, and started to build up
abstractions. They became pretty darn useful, so, this blog post is announcing
(a still incomplete, year old and perhaps API changing) Debian package for Go.
The Go importable name is
As some of the world knows full well by now, I've been noodling with Go
for a few years, working through its pros, its cons, and thinking a lot
about how humans use code to express thoughts and ideas. Go's got a lot of
neat use cases, suited to particular problems, and used in the right place,
you can see some clear massive wins.
I've started writing Debian tooling in Go, because it's a pretty natural fit.
Go's fairly tight, and overhead shouldn't be taken up by your operating system.
After a while, I wound up hitting the usual blockers, and started to build up
abstractions. They became pretty darn useful, so, this blog post is announcing
(a still incomplete, year old and perhaps API changing) Debian package for Go.
The Go importable name is  Slighthly delayed, but here are the stats for week 5 of the
Slighthly delayed, but here are the stats for week 5 of the